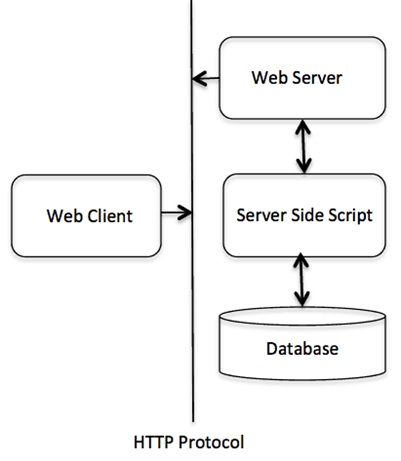
Python Command Line Arguments
Python Command Line Arguments provides a convenient way to accept some information at the command line while running the program. We usually pass these values along with the name of the Python script.
To run a Python program, we execute the following command in the command prompt terminal of the operating system. For example, in windows, the following command is entered in Windows command prompt terminal.
$ python script.py arg1 arg2 arg3
Here Python script name is script.py and rest of the three arguments – arg1 arg2 arg3 are command line arguments for the program.
If the program needs to accept input from the user, Python’s input() function is used. When the program is executed from command line, user input is accepted from the command terminal.
Example
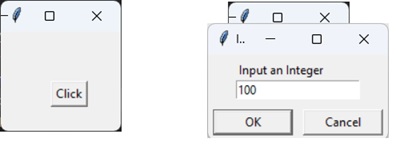
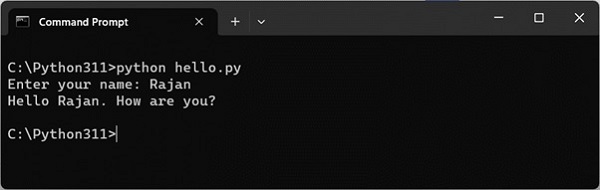
name =input("Enter your name: ")print("Hello {}. How are you?".format(name))The program is run from the command prompt terminal as follows −
Passing Arguments at the Time of Execution
Very often, you may need to put the data to be used by the program in the command line itself and use it inside the program. An example of giving the data in the command line could be any DOS commands in Windows or Linux.
In Windows, you use the following DOS command to rename a file hello.py to hi.py.
C:\Python311>ren hello.py hi.py
In Linux you may use the mv command −
$ mv hello.py hi.py
Here ren or mv are the commands which need the old and new file names. Since they are put in line with the command, they are called command-line arguments.
You can pass values to a Python program from command line. Python collects the arguments in a list object. Python’s sys module provides access to any command-line arguments via the sys.argv variable. sys.argv is the list of command-line arguments and sys.argv[0] is the program i.e. the script name.
Example
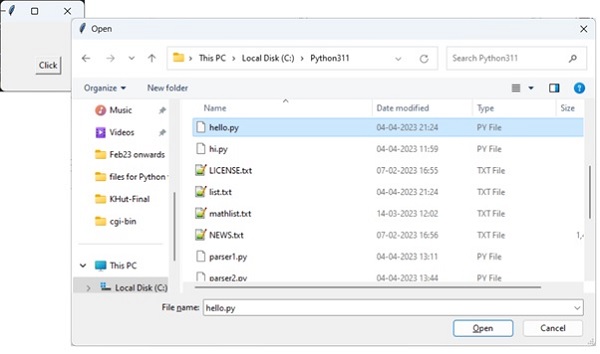
The hello.py script used input() function to accept user input after the script is run. Let us change it to accept input from command line.
import sys
print('argument list', sys.argv)
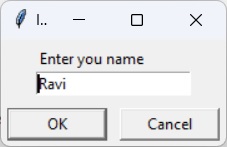
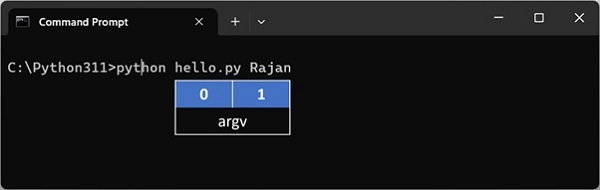
name = sys.argv[1]print("Hello {}. How are you?".format(name))Run the program from command-line as shown in the following figure −
The output is shown below −
C:\Python311>python hello.py Rajan
argument list ['hello.py', 'Rajan']
Hello Rajan. How are you?
The command-line arguments are always stored in string variables. To use them as numerics, you can them suitably with type conversion functions.
Example
In the following example, two numbers are entered as command-line arguments. Inside the program, we use int() function to parse them as integer variables.
import sys
print('argument list', sys.argv)
first =int(sys.argv[1])
second =int(sys.argv[2])print("sum = {}".format(first+second))It will produce the following output −
C:\Python311>python hello.py 1020
argument list['hello.py','10','20']sum=30Python’s standard library includes a couple of useful modules to parse command line arguments and options −
- getopt − C-style parser for command line options.
- argparse − Parser for command-line options, arguments and sub-commands.
Python getopt Module
Python provides a getopt module that helps you parse command-line options and arguments. This module provides two functions and an exception to enable command line argument parsing.
getopt.getopt() method
This method parses the command line options and parameter list. Following is a simple syntax for this method −
getopt.getopt(args, options,[long_options])Here is the detail of the parameters −
- args − This is the argument list to be parsed.
- options − This is the string of option letters that the script wants to recognize, with options that require an argument should be followed by a colon (:).
- long_options − This is an optional parameter and if specified, must be a list of strings with the names of the long options, which should be supported. Long options, which require an argument should be followed by an equal sign (‘=’). To accept only long options, options should be an empty string.
This method returns a value consisting of two elements − the first is a list of (option, value) pairs, the second is a list of program arguments left after the option list was stripped.
Each option-and-value pair returned has the option as its first element, prefixed with a hyphen for short options (e.g., ‘-x’) or two hyphens for long options (e.g., ‘–long-option’).
Exception getopt.GetoptError
This is raised when an unrecognized option is found in the argument list or when an option requiring an argument is given none.
The argument to the exception is a string indicating the cause of the error. The attributes msg and opt give the error message and related option.
Example
Suppose we want to pass two file names through command line and we also want to give an option to check the usage of the script. Usage of the script is as follows −
usage: test.py -i <inputfile>-o <outputfile>Here is the following script to test.py −
import sys, getopt
defmain(argv):
inputfile =''
outputfile =''try:
opts, args = getopt.getopt(argv,"hi:o:",["ifile=","ofile="])except getopt.GetoptError:print('test.py -i <inputfile> -o <outputfile>')
sys.exit(2)for opt, arg in opts:if opt =='-h':print('test.py -i <inputfile> -o <outputfile>')
sys.exit()elif opt in("-i","--ifile"):
inputfile = arg
elif opt in("-o","--ofile"):
outputfile = arg
print('Input file is "', inputfile)print('Output file is "', outputfile)if __name__ =="__main__":
main(sys.argv[1:])Now, run the above script as follows −
$ test.py -h usage: test.py -i <inputfile> -o <outputfile> $ test.py -i BMP -o usage: test.py -i <inputfile> -o <outputfile> $ test.py -i inputfile -o outputfile Input file is " inputfile Output file is " outputfile
Python argparse Module
The argparse module provides tools for writing very easy to use command line interfaces. It handles how to parse the arguments collected in sys.argv list, automatically generate help and issues error message when invalid options are given.
First step to design the command line interface is to set up parser object. This is done by ArgumentParser() function in argparse module. The function can be given an explanatory string as description parameter.
To start with our script will be executed from command line without any arguments. Still use parse_args() method of parser object, which does nothing because there aren’t any arguments given.
import argparse
parser=argparse.ArgumentParser(description="sample argument parser")
args=parser.parse_args()When the above script is run −
C:\Python311>python parser1.py
C:\Python311>python parser1.py -h
usage: parser1.py [-h]
sample argument parser
options:-h,--help show this help message and exit
The second command line usage gives −help option which produces a help message as shown. The −help parameter is available by default.
Now let us define an argument which is mandatory for the script to run and if not given script should throw error. Here we define argument ‘user’ by add_argument() method.
import argparse
parser=argparse.ArgumentParser(description="sample argument parser")
parser.add_argument("user")
args=parser.parse_args()if args.user=="Admin":print("Hello Admin")else:print("Hello Guest")This script’s help now shows one positional argument in the form of ‘user’. The program checks if it’s value is ‘Admin’ or not and prints corresponding message.
C:\Python311>python parser2.py --help
usage: parser2.py [-h] user
sample argument parser
positional arguments:
user
options:-h,--help show this help message and exit
Use the following command −
C:\Python311>python parser2.py Admin Hello Admin
But the following usage displays Hello Guest message.
C:\Python311>python parser2.py Rajan Hello Guest
The add_argument() method
We can assign default value to an argument in add_argument() method.
import argparse
parser=argparse.ArgumentParser(description="sample argument parser")
parser.add_argument("user", nargs='?',default="Admin")
args=parser.parse_args()if args.user=="Admin":print("Hello Admin")else:print("Hello Guest")Here nargs is the number of command-line arguments that should be consumed. ‘?’. One argument will be consumed from the command line if possible, and produced as a single item. If no command-line argument is present, the value from default will be produced.
By default, all arguments are treated as strings. To explicitly mention type of argument, use type parameter in the add_argument() method. All Python data types are valid values of type.
import argparse
parser=argparse.ArgumentParser(description="add numbers")
parser.add_argument("first",type=int)
parser.add_argument("second",type=int)
args=parser.parse_args()
x=args.first
y=args.second
z=x+y
print('addition of {} and {} = {}'.format(x,y,z))It will produce the following output −
C:\Python311>python parser3.py 10 20 addition of 10 and 20 = 30
In the above examples, the arguments are mandatory. To add optional argument, prefix its name by double dash –. In following case surname argument is optional because it is prefixed by double dash (–surname).
import argparse
parser=argparse.ArgumentParser()
parser.add_argument("name")
parser.add_argument("--surname")
args=parser.parse_args()print("My name is ", args.name, end=' ')if args.surname:print(args.surname)A one letter name of argument prefixed by single dash acts as a short name option.
C:\Python311>python parser3.py Anup My name is Anup C:\Python311>python parser3.py Anup --surname Gupta My name is Anup Gupta
If it is desired that an argument should value only from a defined list, it is defined as choices parameter.
import argparse
parser=argparse.ArgumentParser()
parser.add_argument("sub", choices=['Physics','Maths','Biology'])
args=parser.parse_args()print("My subject is ", args.sub)Note that if value of parameter is not from the list, invalid choice error is displayed.
C:\Python311>python parser3.py Physics
My subject is Physics
C:\Python311>python parser3.py History
usage: parser3.py [-h] {Physics,Maths,Biology}
parser3.py: error: argument sub: invalid choice: 'History' (choose from
'Physics', 'Maths', 'Biology')